00:00:00
字符串(KMP & exKMP & AC 自动机 & Manacher & 回文自动机) 笔记
KMP
要求:
匹配上 时,匹配上的第一个字母位于 的位置(如 , ,答案即为 , , )。 每个前缀的 border。
1. 定义
Border:一个字符串最长的相同的前缀和后缀的长度。
文本串:被别人匹配的串,
模式串:匹配别人的串,
2. 理解
为方便表述,下文默认字符串从
---------j
s2: abcabc
s1: abcabab
---------i如图(?),当匹配到这种情况是,暴力的方案是把
---------j
s2: ---abcabc
s1: abcabab
---------i所以,
如上文的例子,就是
容易发现
所以求
求
发现这也恰好是题目要求的 border。
3. 实现
考虑让
cpp
for (int i = 2, j = 0; i <= ns2; i++) {
while (j and s2[i] != s2[j + 1])
j = kmp[j];
if (s2[i] == s2[j + 1])
j++;
kmp[i] = j;
}以 a,因为
但是
但是
然后和文本串匹配:
cpp
for (int i = 1, j = 0; i <= ns1; i++) {
while (j and s1[i] != s2[j + 1])
j = kmp[j];
if (s1[i] == s2[j + 1])
j++;
if (j == ns2) {
cout << i - ns2 + 1 << "\n";
// j == s2.size()说明s2匹配上s1的子串了
// 但是 i 是匹配上的位置的结尾,题目要求开头
j = kmp[j];
// 匹配完了下一位绝对失配,先往前跳
}
}4. 失配树
把
性质:
稍微推导一下即可:
, ,总不可能一段区间的 Border 长度比这段区间还长。 。
代码与 KMP 高度重复,本文重点不是 LCA,故不放。
5. 刷题总结
(1). CF1200E Compress Words
找现在拼好的串的后缀,和新加入的串的前缀,的最长公共长度。考虑到
(2). P4824 [USACO15FEB] Censoring S
用 CSPS 2023 T2
(3). CF126B Password
首先肯定不能直接取
(4). P2375 [NOI2014] 动物园
手玩样例或者瞪眼法都能看出来,当不管是否重复的时候,
接着考虑重复,直接跳 KMP 跳到
(5). P3435 [POI2006] OKR-Periods of Words
只要使得
(6). UVA10298 Power Strings
跟上一题有异曲同工之妙。对若干个周期进行观察,会发现
(7). UVA11022 String Factoring
神秘题目没有数据范围,就朴素的利用 KMP 循环节优化区间 DP
(8). CF526D Om Nom and Necklace
把
(9). CF1286E Fedya the Potter Strikes Back
用
设
,那说明 这个前缀消失了, 。 否则,跳
去寻找更短的前缀,但我们显然可以利用并查集思想,直接 。
接着,我们要减掉这些消失的 border 的权值,其实就是求一个右端点固定区间的最小值,ST 表或二分单调栈均可。还要把没有消失的 border 的权值大于
然后还有两种情况被漏算:一种是第一个字母和第
exKMP
要求:
与 的每一个后缀 的 LCP 长度数组 。 与 的每一个后缀 的 LCP 长度数组 。
1. 定义
LCP:最长公共前缀,即最长的相同的前缀。
2. 处理模式串本身的匹配
初始时,
如果已经处理完
先找
当然
根据
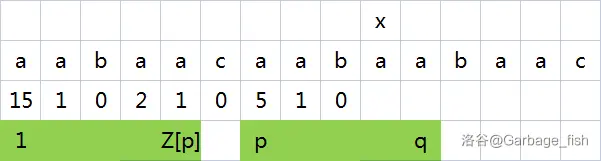
因此,

令
现在有两种情况:
第一种
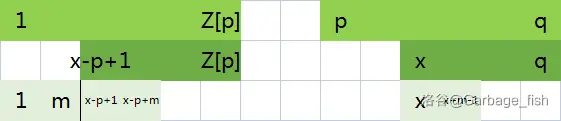
第二种
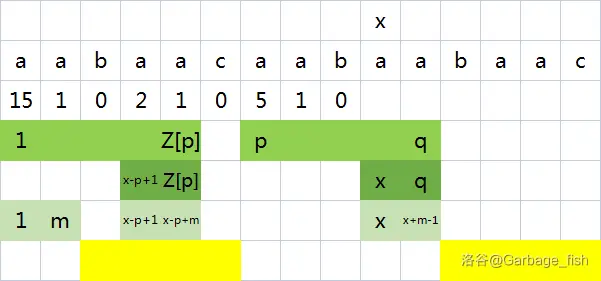
3. 处理模式串与文本串的匹配
思路和求
4. Code
cpp
void solveZ() {
int p = 2, q = 1, m;
Z[1] = lenb;
while (q + 1 <= lenb and b[q] == b[q + 1])
q++;
Z[2] = q - 1;
for (int i = 3; i <= lenb; i++) {
q = p + Z[p] - 1;
m = Z[i - p + 1];
if (i + m - 1 < q)
Z[i] = m;
else {
int j = max(0ll, q - i);
while (i + j <= lenb and b[j + 1] == b[i + j])
j++;
Z[i] = j;
p = i;
}
}
}
void solveP() {
int p = 1, q = 0, m;
while (q < lena and q < lenb and a[q + 1] == b[q + 1])
q++;
P[1] = q;
for (int i = 2; i <= lena; i++) {
q = p + P[p] - 1;
m = Z[i - p + 1];
if (i + m - 1 < q)
P[i] = m;
else {
int j = max(0ll, q - i);
while (i + j <= lena and j < lenb and b[j + 1] == a[i + j])
j++;
P[i] = j;
p = i;
}
}
}AC 自动机
给出
1. 前置知识
Trie。
KMP。
2. 建树和 fail 数组
先把模式串全部建到一个字典树上,在单词的结尾打上一个标记。
cpp
void update(string s) {
int u = 0;
for (int i = 0; i < s.size(); i++) {
if (!trie[u][s[i] - 'a'])
trie[u][s[i] - 'a'] = ++idx;
u = trie[u][s[i] - 'a'];
}
cnt[u]++;
}和 KMP 一样,AC 自动机需要一个
举例说明:
若
, , 。 那么
的 指向 的 , 的 指向 的 。 的 指向 的 的 指向 的 。
发现
首先,每个模式串的第一位的
然后用 BFS 求,流程如下:
如果
存在子节点 ,子节点 在字典树中代表的字符是 , 表示 的儿子中,代表字符 的是 ;则 。 - 如上文的
和 , 失配后指向 ,而两个都在后面加上一个相同的 ,显然 和 仍能匹配。
- 如上文的
如果
不存在子节点 , 的定义上面一样;则 的代表 的儿子直接从 改成 ,继续匹配。 - 如果到
处,下一位字符 会失配,那么肯定会实行不断跳 ,直到一个节点有字符 ,这样地“不断跳”被卡的风险很高,还不如用并查集路径压缩的思想,直接指过去,找的时候也可以直接跳了。
- 如果到
cpp
void get_fail() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++)
if (trie[u][i]) {
fail[trie[u][i]] = trie[fail[u]][i];
q.push(trie[u][i]);
} else
trie[u][i] = trie[fail[u]][i];
}
}3. 询问
直接从字典树往下找,每找到一个串,说明它的所有失配指针指向的串都是可以匹配上的。
为了防止重复遍历,每统计完一个失配指针指向的串就给它打个标记。
(1). 统计有多少个模式串在文本串中出现过
直接给遍历过的点的字典树的结尾标记全部加上即可。
cpp
int query(string s) {
int u = 0, ret = 0;
for (int i = 0; i < s.size(); i++) {
u = trie[u][s[i] - 'a'];
for (int tmp = u; tmp and cnt[tmp] != -1; tmp = fail[tmp]) {
ret += cnt[tmp];
cnt[tmp] = -1;
}
}
return ret;
}(2). 统计出现的次数
把字典树的统计以当前节点结尾的字符串个数:cnt[u]++;,改成这个点代表哪个字符串结尾:
cpp
cnt[u] = id;统计答案的时候就可以拿个数组算这个字符串出现了多少次,由于要统计次数,所以不需要且不能“防止重复遍历”:
cpp
for (int i = 0; i < s.size(); i++) {
u = trie[u][s[i] - 'a'];
for (int tmp = u; tmp; tmp = fail[tmp])
ans[cnt[tmp]].cnt++;
}4. 优化
由于失去了防止重复遍历的 break,上面 3. (2). 中的跳
如
发现由所有
此外,本题还有重复出现的模式串,可以用一个
处理重复(位于 update 函数):
cpp
if (!cnt[u])
cnt[u] = id;
Map[id] = cnt[u];更新时统计以
cpp
if (trie[u][i]) {
fail[trie[u][i]] = trie[fail[u]][i];
idg[fail[trie[u][i]]]++;
q.push(trie[u][i]);
}统计答案时,改为标
cpp
void query(string s) {
int u = 0;
for (int i = 0; i < s.size(); i++) {
u = trie[u][s[i] - 'a'];
tag[u]++;
}
}拓扑排序并合并答案:
cpp
void topsort() {
queue<int> q;
for (int i = 1; i <= idx; i++)
if (!idg[i])
q.push(i);
while (!q.empty()) {
int u = q.front();
q.pop();
ans[cnt[u]] = tag[u];
idg[fail[u]]--;
tag[fail[u]] += tag[u];
if (!idg[fail[u]])
q.push(fail[u]);
}
}5. 刷题总结
(1)/(2). P3121 [USACO15FEB] Censoring G / P4824 [USACO15FEB] Censoring S
后面的弱化版可以用 KMP 做,上面有解法。
还是一样用栈消除操作,只不过这回变成了用 ACAM 匹配,开两个栈一个存 ACAM 节点匹配另一个存答案即可。
(3). P3966 [TJOI2013] 单词
如果
(4).P2444 [POI2000] 病毒
感觉这题也比较板,为啥是紫题?
如果
把字典树和
无限不循环的情况理应不是题目考虑的范围。
然后这里有个小坑,正如小学学的无限循环小数一样,它可以是
(5)/(6). P3041 [USACO12JAN] Video Game G / SP10502 VIDEO - Video game combos
AC 自动机 dp 的常见套路,令
其中
最终的答案即为
(7). P4052 [JSOI2007] 文本生成器
直接算合法的肯定不好搞,总数直接
(8). P3311 [SDOI2014] 数数
这回从 (7) 变成算合法的方案数了,结合数位 dp 和上面同样的 dp 套路即可计算。需要注意处理前导零的情况,另外开一维
(9). CF163E e-Government
首先前面提到的
(10). P2414 [NOI2011] 阿狸的打字机
在
接着优化,根据本题字符串的构造方式,把询问离线下来,在同一个单词里查询的询问一次处理,按照逐步构造单词的顺序选择被查询的单词,可以做到
(11). CF1207G Indie Album
跟 (10) 同理。
Manacher
求字符串
首先,回文串有奇回文串和偶回文串两种,不好处理,如果在每两个字符之间以及开头前和结尾后加入一个间隔符
对于奇回文串,加入了偶数个
,所以还是奇回文串。 对于偶回文串,加入了奇数个
,也变成了奇回文串。
再在字符串的两端加入一个不同的起止符 ~ 和
接下来的思路和 exKMP 很像,设
假设当前求完了
如果的向右遍历到的最大位置是
。
1.
(1).

如上图,根据回文串的定义:
浅蓝色的部分等于深蓝色部分的反串(关于
对称); 左边的深绿色部分等于左边的浅绿色部分的反串(关于
对称); 右边的深绿色部分等于左边的浅绿色部分的反串(关于
对称); 右边的浅绿色部分等于左边的深绿色部分的反串(关于
对称)。
所以右边的浅绿色部分等于右边的深绿色部分的反串。
所以
(2).

和 exKMP 同理,当前不知道黄色的部分能不能匹配的上,所以
2.
直接暴力扩展
最后统计答案,当算上间隔符时,回文串的长度是
cpp
// 插入间隔符
cin >> (tmp + 1);
n = strlen(tmp + 1);
s[1] = '~', s[2] = '#', m = 2;
for (int i = 1; i <= n; i++)
s[m + 1] = tmp[i], s[m + 2] = '#', m += 2;
s[++m] = '!';
// 求最长回文半径
for (int i = 2; i < m; i++) {
if (i <= r)
p[i] = min(p[mid * 2 - i], r - i + 1);
else
p[i] = 1;
while (s[i - p[i]] == s[i + p[i]])
p[i]++;
if (i + p[i] - 1 >= r)
r = i + p[i] - 1, mid = i;
ans = max(ans, p[i] - 1);
}
cout << ans;回文自动机
又叫回文树。
给定字符串
1. 节点定义
每个节点代表一个字符,从一个节点走向根,再从根走回这个节点,经过的节点所代表的字符能构成一个回文串。
因此,每个节点也能代表一个本质不同的回文串。
在一个节点
但是回文串有奇有偶,因此有两个根代表空串:偶根
- 因为奇根下挂的第一层子节点并不需要在空串的两头都加入,只有加入一个才能构成奇串。
除了两个根以外的节点总数就是这个字符串的回文子串总数。
2. 将新回文串放到回文树上的策略
其实模板的问题,换一种说法就是:
对于每个
,求 的回文后缀的个数。
考虑如果已经处理完
所有新加入的回文串
除了
假设现在处理到
。 蓝色部分是
, 的对称中心是 ,浅绿色是一个 。 深绿色是浅绿色的反串(关于
对称)。 浅绿色是浅绿色的反串(它是新加入的回文串)。
深绿色是浅绿色。
由于回文树上的都是本质不同的字符串,深绿色和浅绿色本质相同,故浅绿色不需要添加到回文树上。
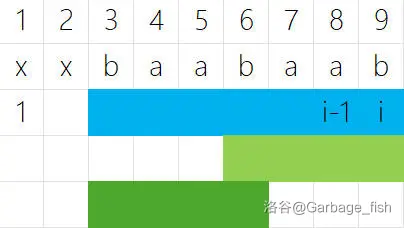
因此,每次只需要把
3. 考虑如何将
类似于 AC 自动机,用类似于字典树的结构来存储回文树,定义
如上文的
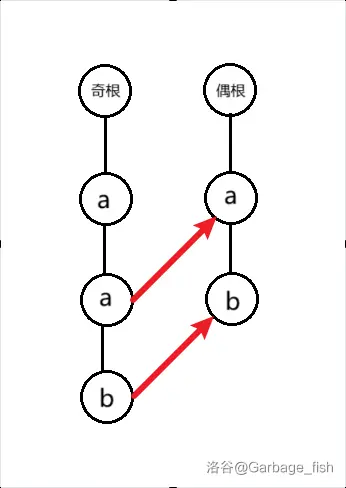
先从代表
根据节点的定义,可以直接将代表
和 AC 自动机一样,
4. 求答案
设
如果
cpp
namespace PAM {
int len[N], num[N], fail[N], trie[N][27], idx = 1, now;
char s[N];
int getfail(int x, int i) {
while (i - len[x] - 1 < 1 or s[i - len[x] - 1] != s[i])
x = fail[x];
return x;
}
void insert(int i) {
int cur = getfail(now, i);
if (!trie[cur][s[i] - 'a']) {
fail[++idx] = trie[getfail(fail[cur], i)][s[i] - 'a'];
trie[cur][s[i] - 'a'] = idx;
len[idx] = len[cur] + 2;
num[idx] = num[fail[idx]] + 1;
}
now = trie[cur][s[i] - 'a'];
}
}
using namespace PAM;
signed main() {
IOS;
cin >> (s + 1);
n = strlen(s + 1);
fail[0] = 1, len[1] = -1;
for (int i = 1; i <= n; i++) {
insert(i);
cout << num[now] << " ";
s[i + 1] = (s[i + 1] + num[now] - 97) % 26 + 97;
}
return 0;
}